Knowledge bases support two primary search methods: semantic search and metadata/keyword search. Each method has its strengths and ideal use cases. Semantic similarity search uses vector embeddings to retrieve content that is semantically related to a given query. This is especially powerful when users are searching for concepts, ideas, or questions expressed in natural language. However, semantic search may fall short when users are looking for specific keywords, such as acronyms, internal terminology, or custom identifiers. These types of terms are often not well-represented in the embedding model’s training data. As a result, embedding-based semantic search might entirely miss results that do contain the exact keyword. To address this gap, knowledge bases offer hybrid search, which combines the best of both worlds: semantic similarity and exact keyword matching. Hybrid search ensures that results relevant by meaning and results matching specific terms are both considered and ranked appropriately.Documentation Index
Fetch the complete documentation index at: https://docs.mindsdb.com/llms.txt
Use this file to discover all available pages before exploring further.
Enabling Hybrid Search
To use hybrid search, you first need to create a knowledge base and insert data into it. Hybrid search can be enabled at the time of querying the knowledge base by specifying the appropriate configuration options, as shown below.hybrid_search_alpha parameter enables hybrid search functionality and allows you to control the balance between semantic and keyword relevance, with values varying between 0 (more importance on keyword relevance) and 1 (more importance on semantic relevance) and the default value of 0.5.
Alternatively, you can use the hybrid_search parameter and set it to true in order to enable hybrid search with default hybrid_search_alpha = 0.5.
Note that hybrid search works only on knowledge bases that use PGVector as a storage. Ensure to install the PGVector handler to connect it to MindsDB.
reranking = false, which might be desirable for performance reasons or specific use cases. When reranking is disabled, the system still needs to combine the two search result sets. In this case, the final ranking of each document is computed as a weighted average of the embedding similarity score and the BM25 keyword relevance score from the full-text search.
Relevance-Based Document Selection for RerankingWhen retrieving documents from the full-text index, there is a practical limit on how many documents can be passed to the reranker, since reranking is typically computationally expensive. To ensure that only the most promising candidates are selected for reranking, we apply relevance heuristics during the keyword search stage.One widely used heuristic is BM25, a ranking function that scores documents based on their keyword relevance to the user query. BM25 considers both the frequency of a keyword within a document and how common that keyword is across the entire corpus.By scoring documents using BM25, the system can prioritize more relevant matches and limit reranker input to a smaller, high-quality subset of documents. This helps achieve a balance between performance and retrieval accuracy in hybrid search.
Implementation of Hybrid Search
Hybrid search in knowledge bases combines semantic similarity and keyword-based search methods into a unified search mechanism. The diagram below illustrates the hybrid search process.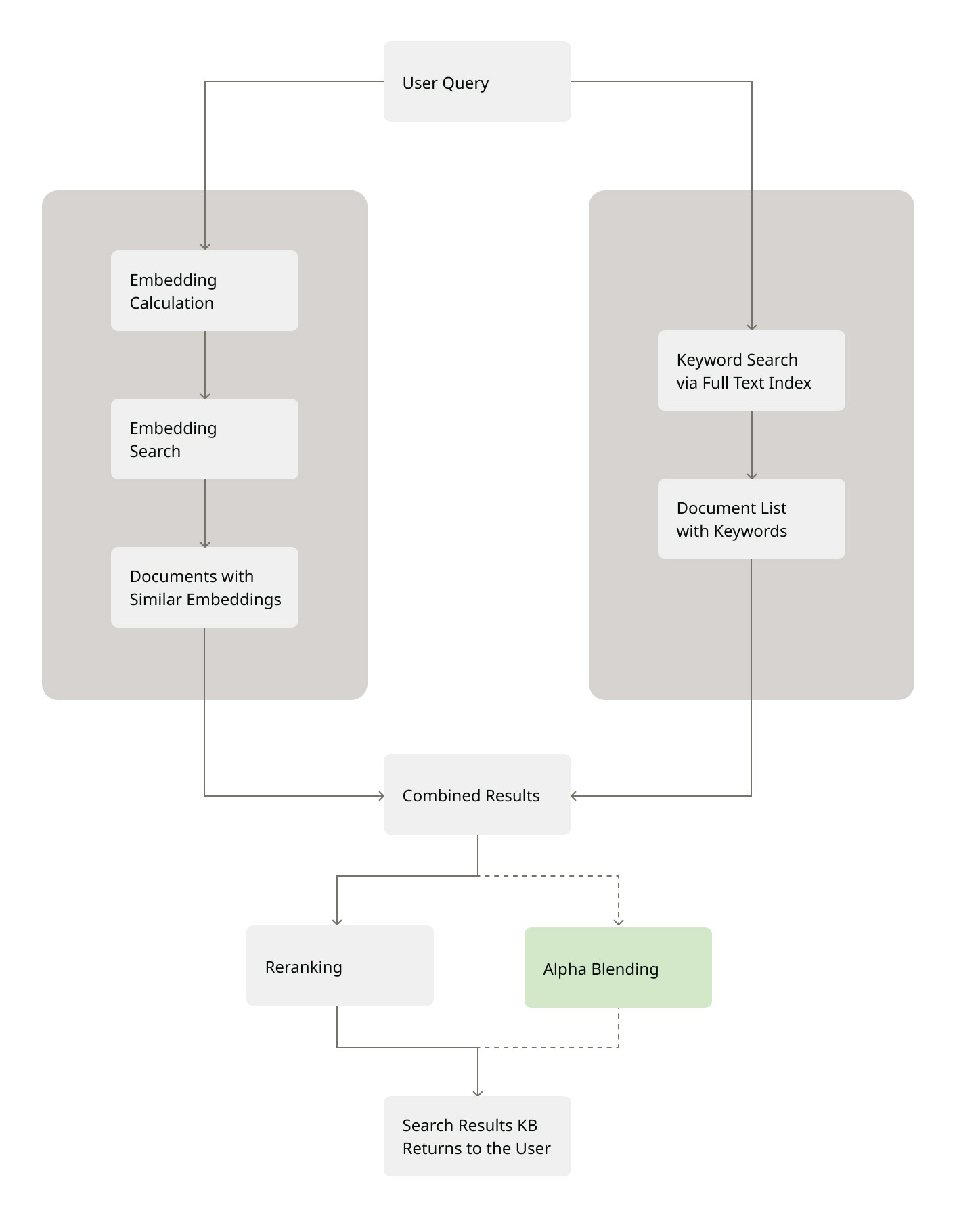
- Semantic Search (path on the left) It takes place in parallel with the keyword search. Semantic search starts by embedding the search query and searching against the content of the knowledge base. This results in a set of relevant documents found.
-
Keyword Search (path on the right)
It takes place in parallel with the semantic search. The system performs a keyword-based search, using one or more keywords provided in the search query, over the content of the knowledge base. To ensure performance, especially at scale, when dealing with millions of documents, we rely on a full-text indexing system.
This index is typically built as an inverted index, mapping keywords to the documents in which they appear. It allows for efficient lookups and rapid retrieval of all entries that contain the given terms.
This step ensures that exact matches, like specific acronyms, ticket numbers, or product identifiers, can be found quickly, even if the semantic model wouldn’t have surfaced them.Storage of Full-Text IndexJust as embeddings are stored to support semantic similarity search, a full-text index must also be stored to enable efficient keyword-based retrieval. This index serves as the foundation for fast and scalable full-text search and is tightly integrated with the knowledge base.Each knowledge base maintains its own dedicated full-text index, built and updated as documents are ingested or modified. Maintaining this index alongside the stored embeddings ensures that both semantic and keyword search capabilities are always available and performant, forming the backbone of hybrid search.
- Combining Results At this step, results from both searches are merged. Semantic search returned documents similar in meaning to the user’s query using embeddings, while keyword search returned documents containing the keywords extracted from the user’s query. This complete result set is passed to the reranker.
-
Reranking
The results are reranked, considering relevance scores from both search types, and ordered accordingly.
There are two mechanisms for reranking the results:
-
Using the reranking model of the knowledge base
If the knowledge base was created with the reranking model provided, the hybrid search uses it to rerank the result set.
In this query, the hybrid search uses the reranking features enabled with the knowledge base.
-
Using the alpha reranking that can be further customized for hybrid search
Users can opt for using the alpha reranking that can be customized specifically for hybrid search. By setting the
hybrid_search_alphaparameter to any value between 0 and 1, users can give importance to results from the keyword search (if the value is closer to 0) or the semantic search (if the value is closer to 1).This query uses hybrid search with emphasis on results from the keyword search.Relevance-Based Document Selection for RerankingWhen retrieving documents from the full-text index, there is a practical limit on how many documents can be passed to the reranker, since reranking is typically computationally expensive. To ensure that only the most promising candidates are selected for reranking, we apply relevance heuristics during the keyword search stage.One widely used heuristic is BM25, a ranking function that scores documents based on their keyword relevance to the user query. BM25 considers both the frequency of a keyword within a document and how common that keyword is across the entire corpus.By scoring documents using BM25, the system can prioritize more relevant matches and limit reranker input to a smaller, high-quality subset of documents. This helps achieve a balance between performance and retrieval accuracy in hybrid search.
-
Using the reranking model of the knowledge base
If the knowledge base was created with the reranking model provided, the hybrid search uses it to rerank the result set.